
مفهوم NUMA یک تعریف بسیار مهم در مبحث بهینه سازی کارآیی سیستم می باشد. توجه به موضوع NUMA و نحوه اجرای آن بر روی سیستم عامل می تواند تاثیر بسزایی در روند بهینه سازی عملکرد سیستم شما ایجاد نماید.
مفهوم NUMA در محیط مجازی از 3 منظر زیر قابل بررسی است. اما قبل از آغاز مطالب، در نظر داشته باشید که در توضیحات و مثال های بیان شده، نوع سرور فیزیکی مدنظر یک سرور Dual Socket CPU می باشد.
اما قبل از اینکه وارد مبحث NUMA شویم، بهتر است با مفهوم UMA آشنا شویم. مفهوم UMA یا Uniform Memory Access در پردازنده های قبل نسل Nehalem اینتل و Opteron شرکت AMD وجود داشت. این مفهوم بدین شکل عمل میکند که تمام DIMM های حافظه اصلی موجود روی یک مادربرد در اختیار تمام سوکت های CPU نصب شده روی آن مادربرد قرار داده می شوند. در اینصورت تمام پردازنده ها به صورت یکسان از DIMM ها بهره برداری کرده و طبیعتا در صورت بروز Latency نیز همین یکسان سازی بین تمام پردازش های صورت گرفته توسط CPU ها وجود خواهد داشت.
علت این امر نیز وجود بخشی به نام Memory Controller بر روی مادربرد بود که تمام سوکت های CPU جهت دسترسی به اطلاعات حافظه های اصلی از این بخش استفاده می کردند. در کنار این MC نیز یک بخش دیگری به نام IO Controller وجود داشت که فرآیند کنترلی درخواست های CPU به MC را مدیریت می کرد. این وضعیت در Workload های بسیار سنگین یک ضعف بزرگ محسوب میشد، در نتیجه شرکت های بزرگی همچون اینتل و AMD در پی رفع این مشکل، مفهوم جدیدی به نام NUMA را ایجاد کردند.
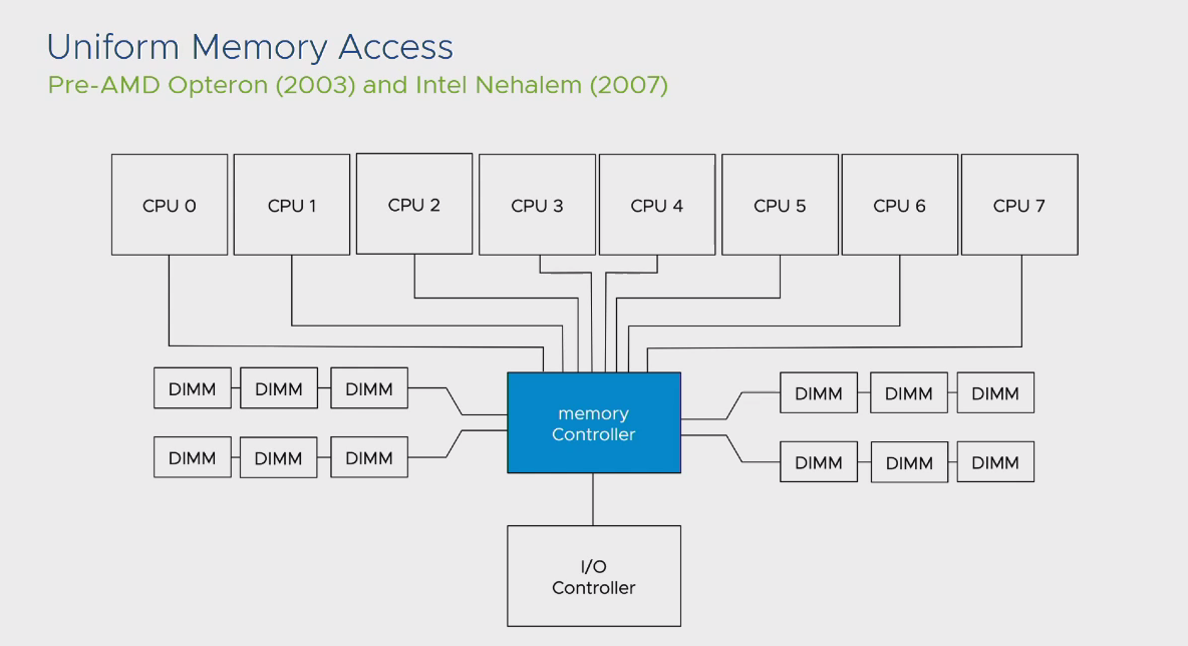
بررسی از منظر لایه فیزیکی
مفهوم NUMA یا Non-Uniform Memory Access توسط شرکت اینتل بر روی پردازنده های نسل Nehalem و بعد از آن معرفی شد. موارد زیر تغییرات بزرگی بود که با ظهور این مفهوم ایجاد شد:
در این شرایط هر سوکت CPU نصب شده روی مادربرد به DIMM هایی به صورت مستقیم دسترسی پیدا میکرد که در اختیار آن سوکت قرار داده شده بود. به طور مثال برای یک سرور که از قابلیت Dual CPU Socket پشتیبانی میکند و دارای 24 بخش برای حافظه اصلی است، 12 بخش برای یک سوکت و 12 بخش دیگر برای سوکت دوم به عنوان Local Memory در نظر گرفته می شود.
حال سوال اینجاست که اگر اطلاعات موجود که قرار است بر روی حافظه های اصلی قرار داده شود تا در نهایت توسط پردازنده پردازش شود بیش از میزان حافظه های نصب شده روی یک Local Memory باشد چه اتفاقی خواهد افتاد؟ پاسخ به این سوال به مفهوم QPI منتهی شد. اتصال هر سوکت CPU به Remote Memory سایر سوکت های نصب شده روی مادربرد، توسط لینک ارتباطی QPI انجام می گیرد.
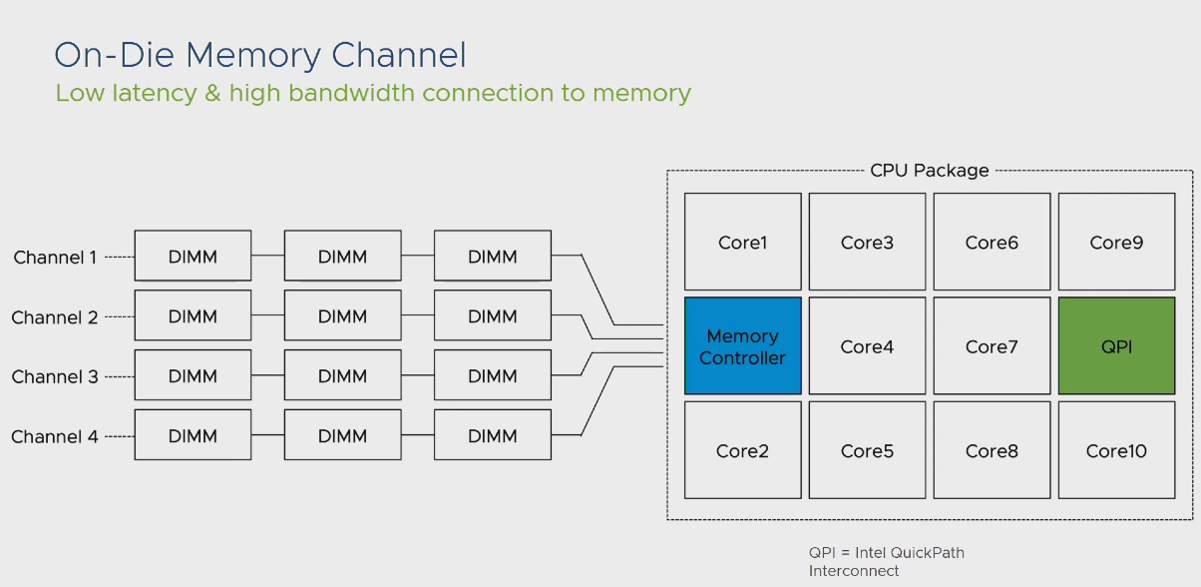
نکته بسیار مهمی که در این بخش وجود دارد این است که این لینک ارتباطی دارای محدودیت پهنای باند است، لذا در صورتیکه یک CPU بخواهد بخش اعظمی از اطلاعات خود را از طریق Remote Memory تامین نماید قطعا با مشکل Performance روبرو خواهد شد.
به هر کدام از بخش هایی که شامل یک سوکت CPU و تعدادی DIMM حافظه اصلی به عنوان Local Memory به اصلاح NUMA Node گفته می شود.
یکی دیگر از مشکلات موجود در نسل های ابتدایی که معرفی شد این بود که تعداد Channel های موجود جهت اتصال CPU به DIMM های حافظه اصلی محدود به 4 عدد بود. در این شرایط اگر تمام DIMM های یک مادربرد به صورت Full استفاده میشد، به اصطلاح Channel های موجود Noisy شده و با افت کارآیی سیستم مواجه می شدیم. در این شرایط بخش MC موجود در پردازنده فرآیند کنترل IO را اجرا کرده و فرکانس ارتباطی CPU یا DIMM ها را کاهش میداد تا شرایط Noisy شدن Channel ها را به حداقل برساند. به طور مثال اگر تمام DIMM های شما توسط Memory های سری 2400 پر شده بودند، این کاهش فرکانس در زمان Noisy بودن Channel ها تا 1866 نیز مشاهده می شد.
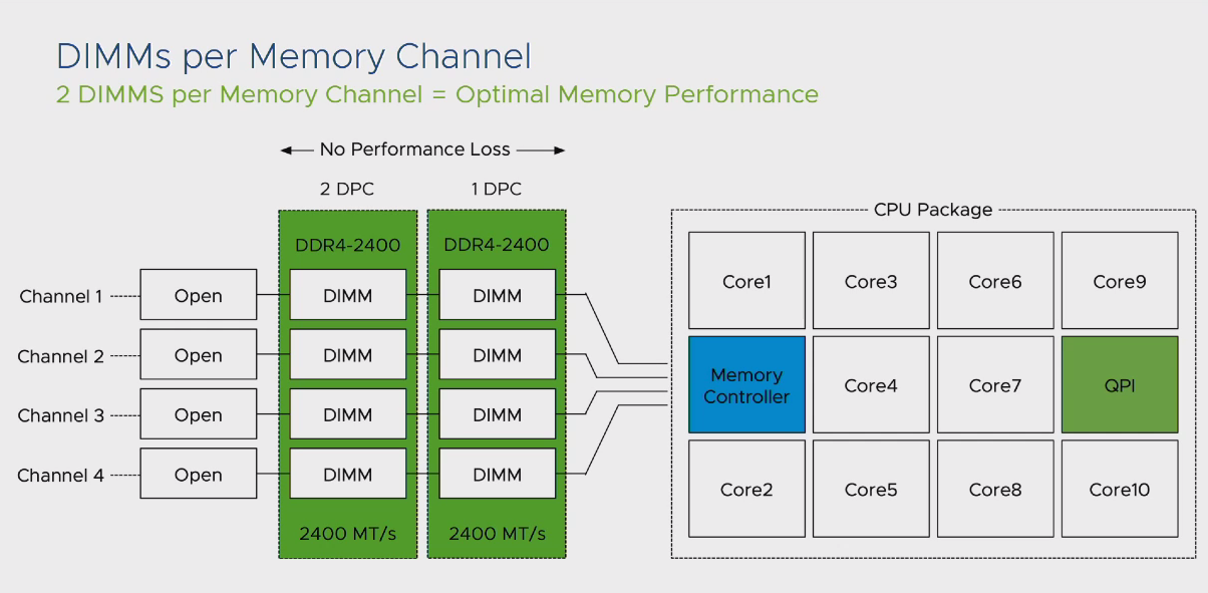
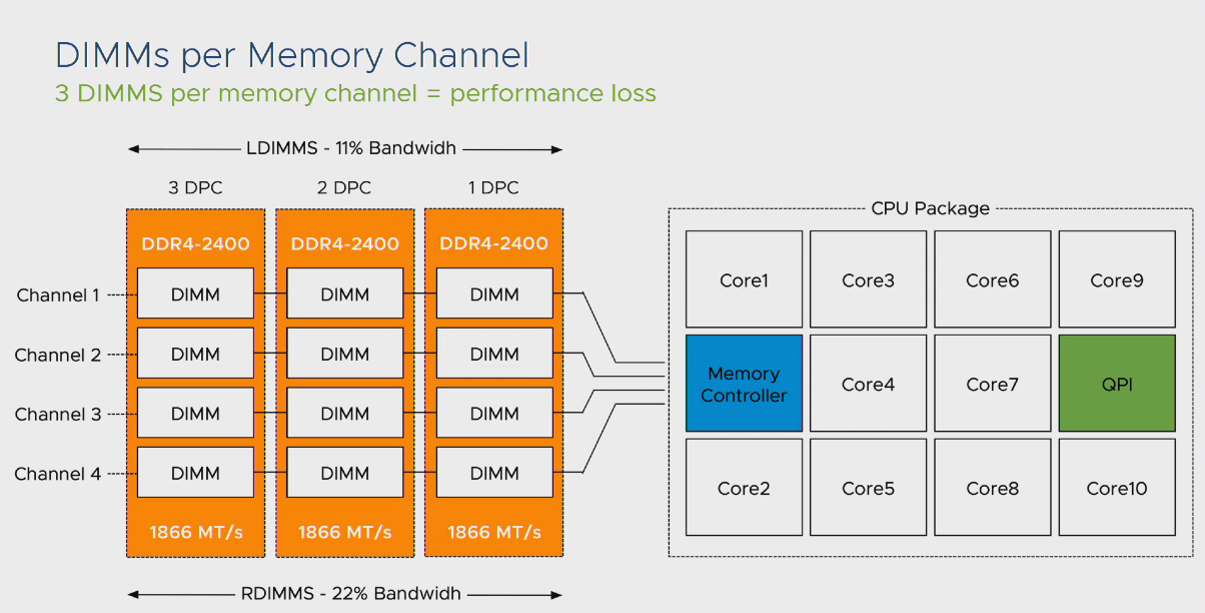
از منظر بهروش های موجود، افزایش ظرفیت حافظه اصلی بر مبنای Memory Module و نه افزایش تعداد DIMM ها پیشنهاد میشود. به طور مثال برای سیستمی با ظرفیت 128 گیگابایت حافظه اصلی، 4 ماژول 32 گیگابایتی عملکرد بهتری نسبت به 16 ماژول 8 گیگابایتی خواهد داشت. به صورت کلی این کاهش کارآیی در Memory های سری RDIMM تا 22 درصد و برای Memory های سری LDIMM تا 11 درصد مشهود بود.
در چنین شرایطی شرکت اینتل نسل جدید CPU های خود را با عنوان Skylake یا Intel Scalable Family عرضه کرد. تفاوت های چشمگیری که در این نسل ایجاد شد به شرح زیر است:
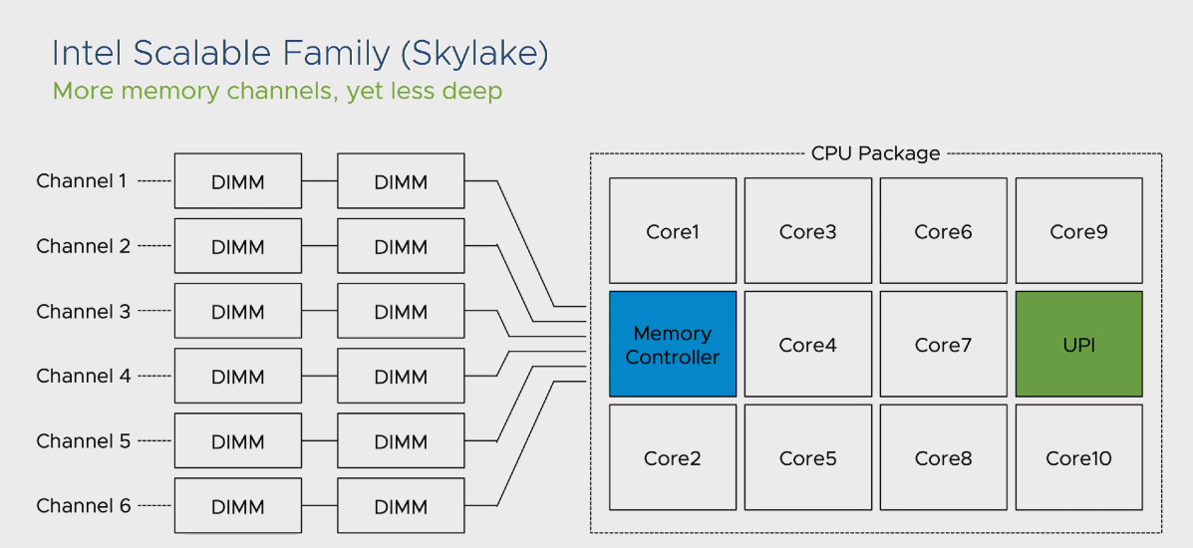
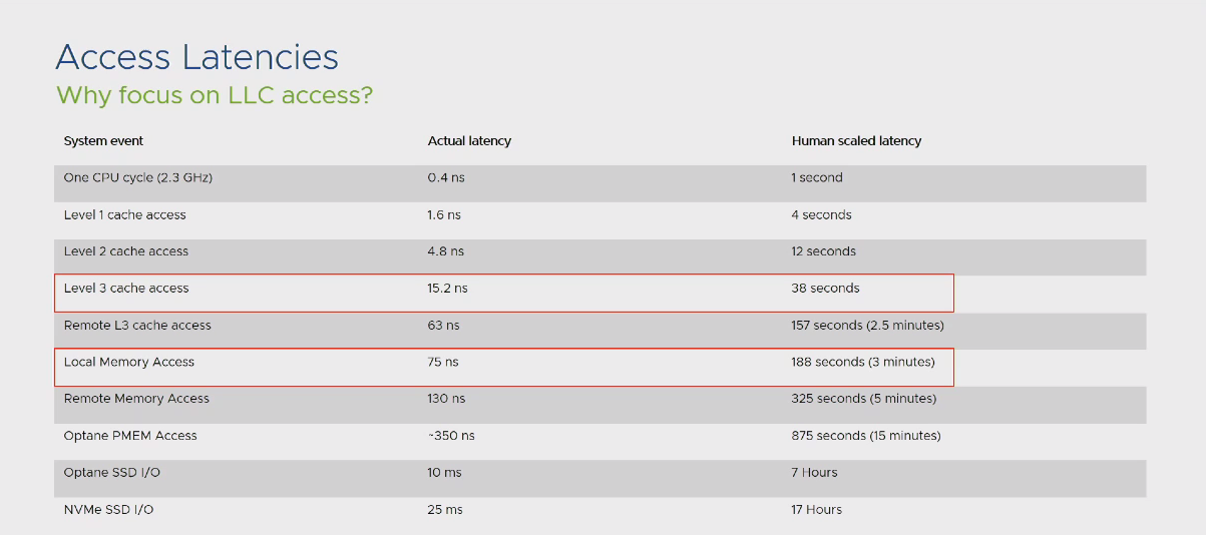
با این تغییرات شرایط کارآیی سیستم حتی در مواجه با فرآیند استفاده از Remote Memory جهش خوبی از خود نشان داد. اما به منظور درک بهتر موضوع NUMA Node ها حتی در نسل های جدید CPU به مثال زیر توجه نمایید:
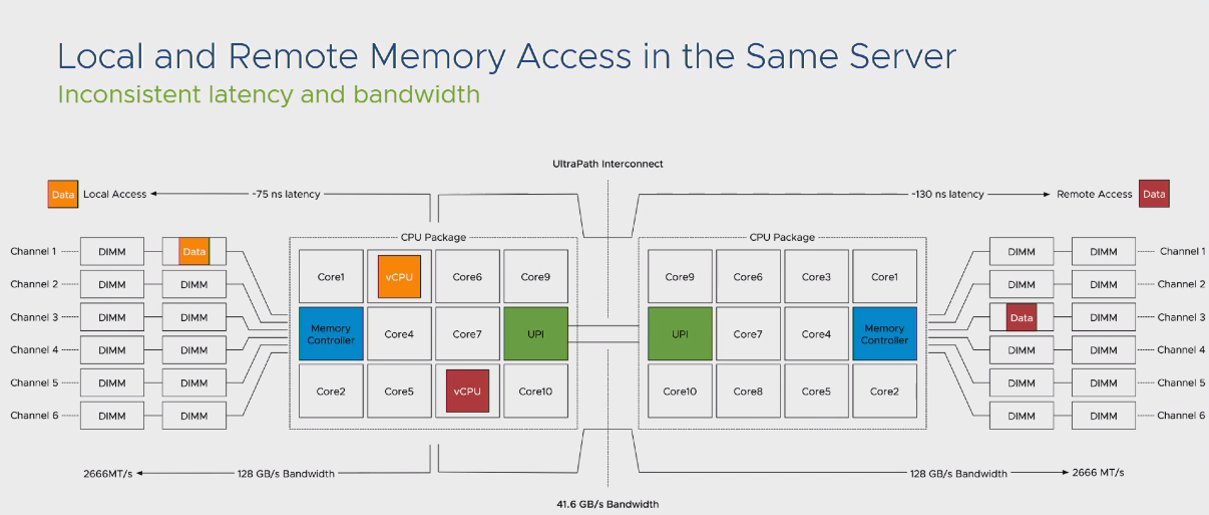
در این مثال تفاوت تاخیر پاسخگویی در شرایط Local Memory و Remote Memory را مشاهده میکنید. در نتیجه بهترین شرایط کارآیی آنست که بتوانیم اپلیکیشن های خود را درون یک NUMA Node قرار دهیم.
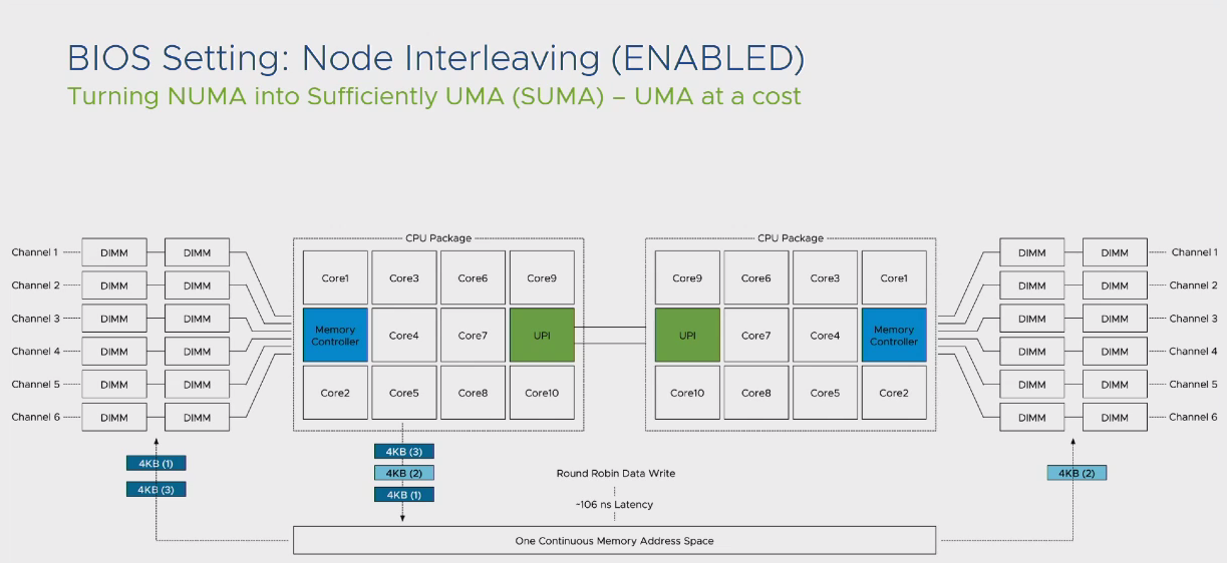
نکته: برای اپلیکیشن هایی که به اصطلاح NUMA Aware نیستند، ویژگی بهره مندی از UMA با عنوان Node Interleaving در بخش تنظیمات BIOS مادربرد قرار داده شده است. این بخش به صورت پیش فرض غیرفعال است که با فعال کردن آن ویژگی UMA با ویژگی NUMA جایگزین می شود. پس براساس آنچه که تا به اینجا گفته شد، تغییرات در این بخش را با دقت بسیار و با توجه به نوع Workload خود انجام دهید. زمانیکه ویژگی Node Interleaving در مادربرد فعال می شود، تمام دیتای ورودی به Memory های نصب شده روی مادربرد، به صورت Round Robin و با اندازه 4KB روی ماژول های Memory قرار داده می شوند. در اینصورت تاخیر پاسخگویی به میانگین تاخیر پاسخگویی در حالت Local Memory و Remote Memory تغییر میکند و فرآیند پاسخدهی به پردازش ها از منظر Latency یک فرآیند کاملا ناپایدار خواهد بود.
بررسی لایه VMKernel
سرویس ESXi نیز از ویژگی NUMA بی بهره نیست و کاملا NUMA Aware رفتار می نماید. ویژگی NUMA در فرآیندهای توسعه این سرویس یکی از مهمترین عناصر می باشد و در هر نسخه ارائه شده توسط شرکت VMware شاهد تغییرات اساسی در این بخش هستیم. اگر بخواهیم به صورت کلی نگاهی به وضعیت مدیریت NUMA توسط هاست ESXi بیاندازیم، تصویر زیر گویا خواهد بود:
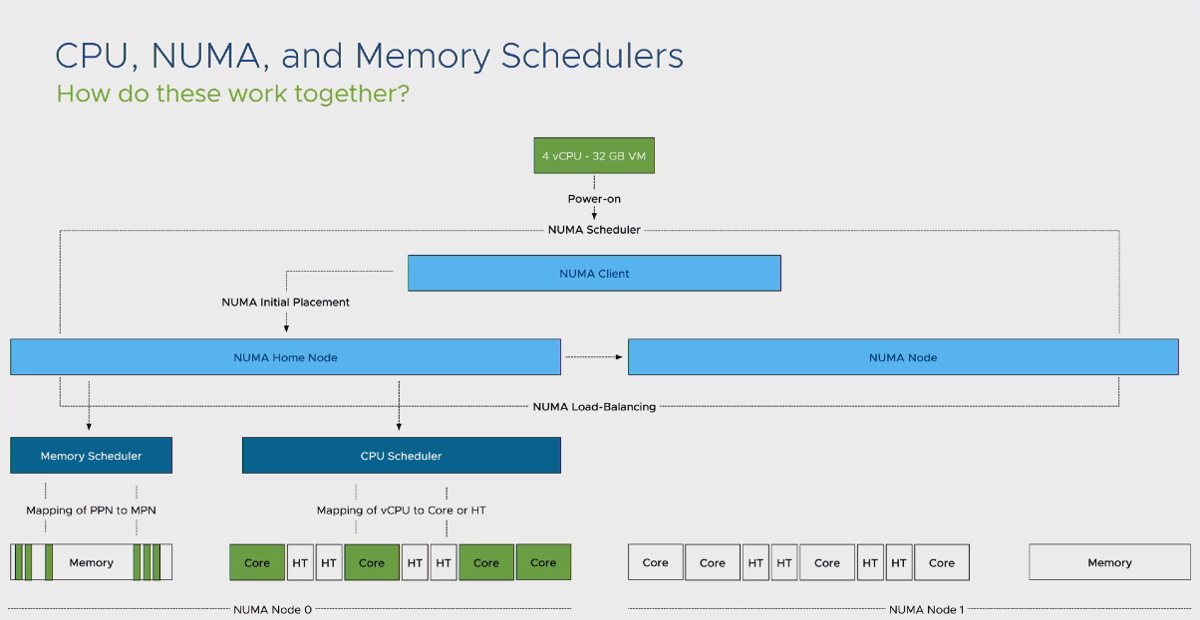
در این تصویر یک ماشین مجازی با 4 عدد vCPU و 32 گیگابایت حافظه اصلی ایجاد و روشن شده است. در این شرایط مفهومی به نام NUMA Scheduler برای ماشین مجازی اجرا می شود. این ویژگی بررسی می نماید که آیا این ماشین مجازی درون یک NUMA Node قرار می گیرد یا خیر. در صورتیکه پاسخ مثبت باشد، فرآیند ایجاد NUMA به NUMA Client سپرده میشود. در این بخش NUMA Client به بخش CPU Scheduler اعلام میکند که تنظیمات این ماشین مجازی به صورتی است که امکان قرار گرفتن درون یک سوکت CPU و یا حافظه های اصلی را دارد و از این قسمت به بعد، فرآیند Scheduling توسط CPU Scheduler درون یک سوکت CPU انجام می شود.
براساس توضیحات داده شده در بالا، از منظر Guest OS، یک سیستم عامل با یک NUMA Node ایجاد شده است و تمام اپلیکیشن هایی که NUMA Aware می باشند، خود را با این شرایط Optimize می کنند. فلوچارت زیر فرآیند کلی توضیحات داده شده در بالا را به تصویر می کشد:
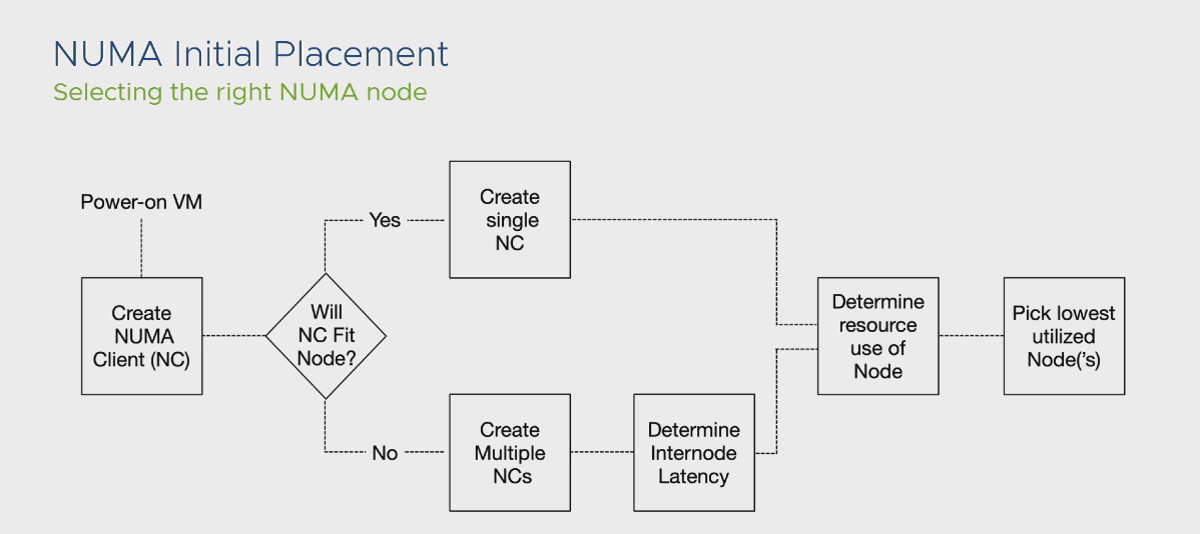
در کل مزایایی که NUMA Scheduler در ساختار ESXi قرار داده شد به شرح زیر است:
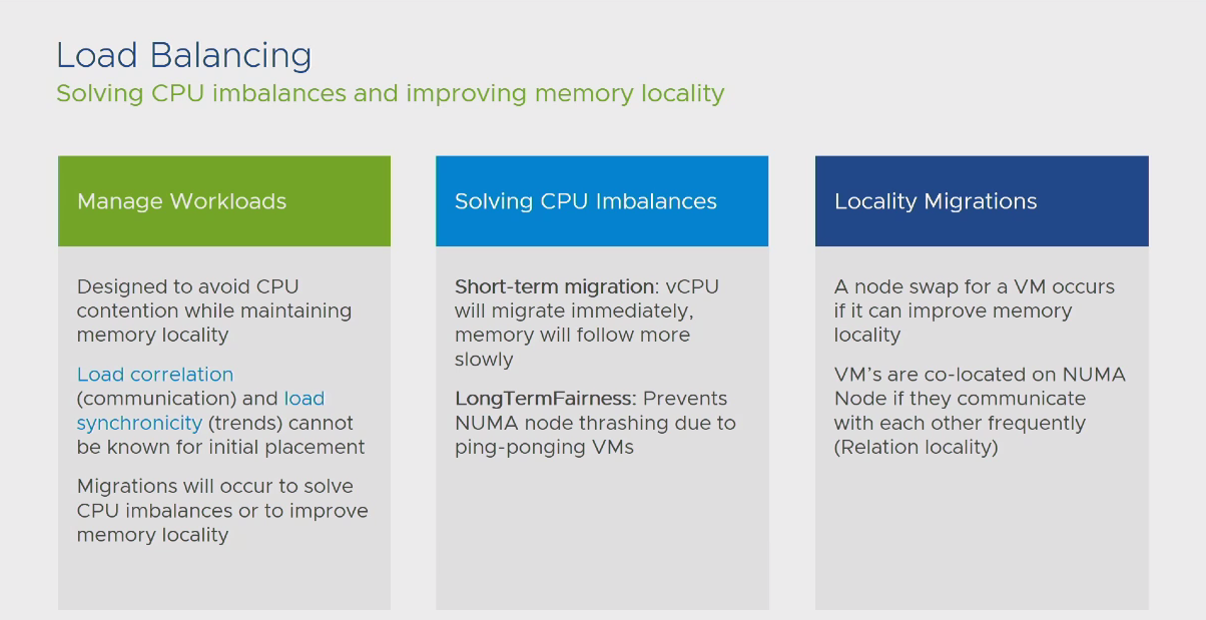
نکته: از منظر Data Placement درون یک سرور و دسترسی پردازنده به آن اطلاعات، 2 بخش مهم وجود دارد. بخش اول L3 Cache و بخش دوم Memory های نصب شده روی سرور می باشد. محصول ESXi به منظور کاهش میزان Latency فرآیندهای پردازشی به دلیل شرایط دسترسی به اطلاعات مورد نیاز، ویژگی با عنوان Action Affinity را درون خود جای داده است. براساس این ویژگی، تمام vCPU هایی که به یک دیتای مشترک نیاز دارند و یا با یکدیگر در ارتباط هستند درون یک سوکت CPU اصطلاحا Schedule می شوند. در اینصورت میزان Latency در فرآیند پردازشی، معادل تاخیر زمانی دسترسی CPU به L3 Cache می باشد که در مقایسه با دسترسی CPU به اطلاعات درون Memory عدد بسیار کمتری می باشد.
مشکلی که در زمان بهره برداری از این ویژگی با آن مواجه می شویم، Overload شدن یک NUMA Node نسبت به Node دیگر می باشد. در این صورت اگر خروجی دستور ESXTOP و بخش Memory را مشاهده کنید، می بینید که تعداد ماشین های قرار داده شده روی یک NUMA Home بیش از سایر NUMA Home های دیگر می باشد و این بدین معنا نیست که فرآیند NUMA Scheduler با شکست مواجه شده است. این امر تنها سبب می شود تا Domain های کوچکتری در اختیار هر ماشین مجازی قرار گیرد و در نتیجه ماشین های مجازی با واقعه Contention در سطح CPU مواجه شوند. اما به دلیل اینکه NUMA Scheduler یک فرآیند کاملا Dynamic است، بدین معنا که حتی پس از روشن شدن ماشین مجازی نیز در صورت نیاز اقدام به جابجا کردن NUMA Node ها میکند، می تواند این Contention ایجاد شده را مدیریت کرده و از بروز افت کارآیی سیستم ها جلوگیری کند. حال اگر نوع Workload های موجود در مجموعه شما با این شرایط منطبق نیستند، می توانید این ویژگی را غیرفعال کنید.
غیر فعال کردن این ویژگی در سطح هاست ESXi با تغییر numa.LocalityWeightActionAffinity انجام می شود و این بدین معناست که تمام ماشین های مجازی موجود بر روی آن هاست از این تغییر بهره می برند، بنابراین این تغییر را با دقت بسیار زیاد انجام دهید. برای اطلاعات بیشتر می توانید KB منتشر شده با شماره 2097369 را مطالعه نمایید.
همانطور که قبلا نیز اشاره شد، در هر نسخه از ESXi که توسط شرکت VMware ارائه می شود، تغییرات اساسی در ساختار NUMA و فرآیندهای CPU Scheduling رخ میدهد. در تصویر زیر می توانید تفاوت این تغییرات را از گذشته تا نسخه 6.7 آپدیت 2 مشاهده نمایید.
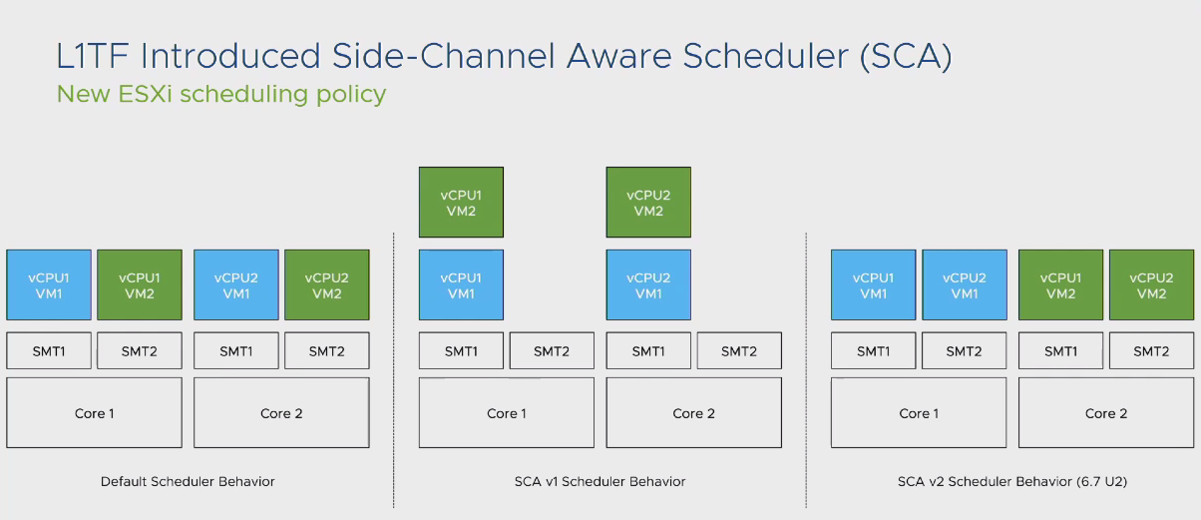
همانطور که از تصویر کاملا مشخص است، در نسخه های قدیمی فرآیند CPU Scheduling و NUMA Scheduler باعث می شد تا ماشین های مجازی در صف یکدیگر قرار بگیرند. به طور مثال اگر 2 ماشین مجازی با تعداد 2 عدد vCPU بر روی سوکت های فیزیکی Schedule می شدند، یک vCPU از یک ماشین مجازی در کنار یک vCPU از ماشین مجازی روی یک هسته فیزیکی قرار داده میشد، در اینصورت تا اتمام فرآیند پاسخدهی به نیاز vCPU ماشین مجازی اول، vCPU ماشین مجازی دوم می بایست در صف قرار می گرفت و بعضا برای Workload های بزرگ این صف طولانی شده و منجر به بروز CPU Ready Time های بالا می شد.
در نسخه 6.7 آپدیت 2 تغییراتی که در سطح CPU Scheduling رخ داد باعث شد تا حد امکان تمام vCPU های یک ماشین مجازی درون یک هسته فیزیکی Schedule شود. این شرایط باعث بهینه تر شدن وضعیت کارآیی ماشین های مجازی گشت. لذا نکته ای که در این بخش وجود دارد این است که تا حد امکان به نسخ بروز ESXi مهاجرت نمایید تا بتوانید از این تغییرات بهره مند شوید.
از منظر VMkernel فرآیند NUMA Scheduler به تعداد هسته های فیزیکی یک سوکت CPU وابسته است. بدین معنا که اگر تعداد vCPU های تخصیص داده شده به یک ماشین مجازی از تعداد هسته های فیزیکی یک سوکت CPU بیشتر باشد، فرآیند NUMA Scheduler آن ماشین مجازی را درون NUMA Node های بیشتری قرار میدهد. برای شرایطی که اپلیکیشن Cache Intensive است و یا قصد دارید به دلیل استفاده کامل از Local Memory ماشین مجازی را درون یک NUMA Node قرار دهید، هاست ESXi این امکان را به شما میدهد تا بتوانید شمارنده هسته های فیزیکی CPU را به Hyper-threading تغییر دهید.
در اینصورت زمانیکه ماشین مجازی روشن می شود، تعداد هسته های فیزیکی یک سوکت CPU درنظر گرفته نمیشود، بلکه تعداد HT های آن سوکت که 2 برابر تعداد هسته های فیزیکی است در نظر گرفته خواهد شد. در این شرایط برای ماشین مجازی که قبلا بین دو NUMA Node تقسیم میشد، یک NUMA Node تخصیص داده می شود که این امر برای سناریوهای گفته شده در بالا می تواند در فرآیند افزایش کارآیی سیستم موثر باشد. برای اینکار می توانید از تنظیمات پیشرفته numa.PreferHT در سطح هاست یا numa.vcpu.PreferHT در سطح ماشین مجازی مدنظر خود استفاده نمایید. برای اطلاعات بیشتر در این بخش می توانید KB منتشر شده با شماره 2003582 را مطالعه نمایید.
بررسی از منظر لایه Workload
قبل از اینکه وارد مبحث Workload شویم می بایست با برخی از Counter های موجود در خروجی دستور ESXTOP آشنا شویم. زمانیکه از این دستور استفاده میکنید، در بخش Memory (با فشردن کلید M می توانید وارد این بخش شوید) مقادیر زیر بسیار حائز اهمیت می باشند:
در صورتیکه از تنظیمات پیش فرض ESXi استفاده میکنید، همیشه سعی نمایید تا این مقادیر را در سطح هر هاست خود مانیتور نمایید. حال میخواهیم به بررسی لایه Workload بپردازیم. از منظر این لایه، زمانیکه یک ماشین مجازی روشن می شود، فرآیند زیر رخ میدهد:
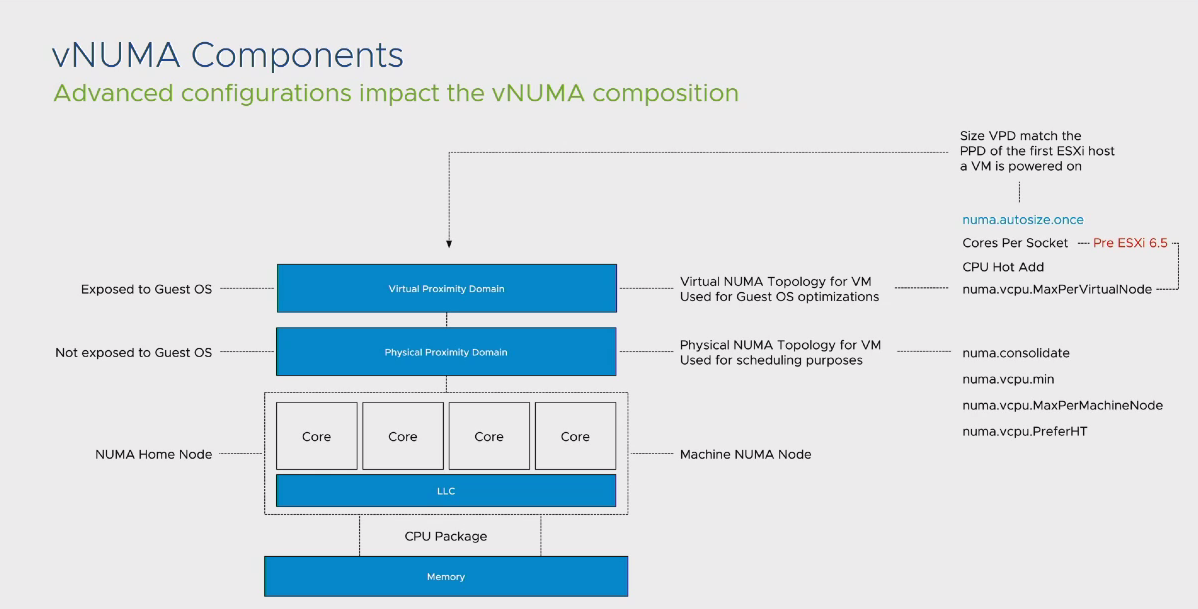
در این فرآیند دو مفهوم PPD یا Physical Proximity Domain و VPD یا Virtual Proximity Domain قرار داده شده اند. اما این دو مفهوم چه کارآیی دارند؟
زمانیکه صحبت از NUMA در محیط مجازی می کنیم، باید در نهایت به این نتیجه برسیم که Guest OS نصب شده بر روی ماشین مجازی از اینکه از NUMA می تواند بهره برداری کند یا خیر آگاه باشد. این آگاهی توسط بخشی به نام VPD به سیستم عامل مجازی ما Expose می شود. در لایه پایین تر، هر VPD به یک PPD به اصطلاح MAP شده تا در نهایت توسط CPU Scheduler فرآیند تخصیص هسته های فیزیکی به vCPU های این ماشین مجازی انجام شود. طبق تصویر بالا، می توانید تنظیمات تاثیرگذار در هر بخش را نیز مشاهده نمایید.
نکته: براساس تنظیمات پیش فرض ESXi زمانیکه شما یک ماشین مجازی ایجاد میکنید، در 2 حالت فرآیند Multi NUMA برای ماشین مجازی اجرا می شود. حالت اول افزایش تعداد vCPU های ماشین مجازی به بیش از 8 عدد و حالت دوم بیشتر بودن تعداد vCPU های تخصیص داده شده به ماشین مجازی بیش از تعداد هسته های فیزیکی موجود بر روی یک سوکت فیزیکی می باشد. باید توجه داشته باشید که هر کدام از این حالت ها قابل تغییر است. تصویر زیر گویای این مطلب می باشد:
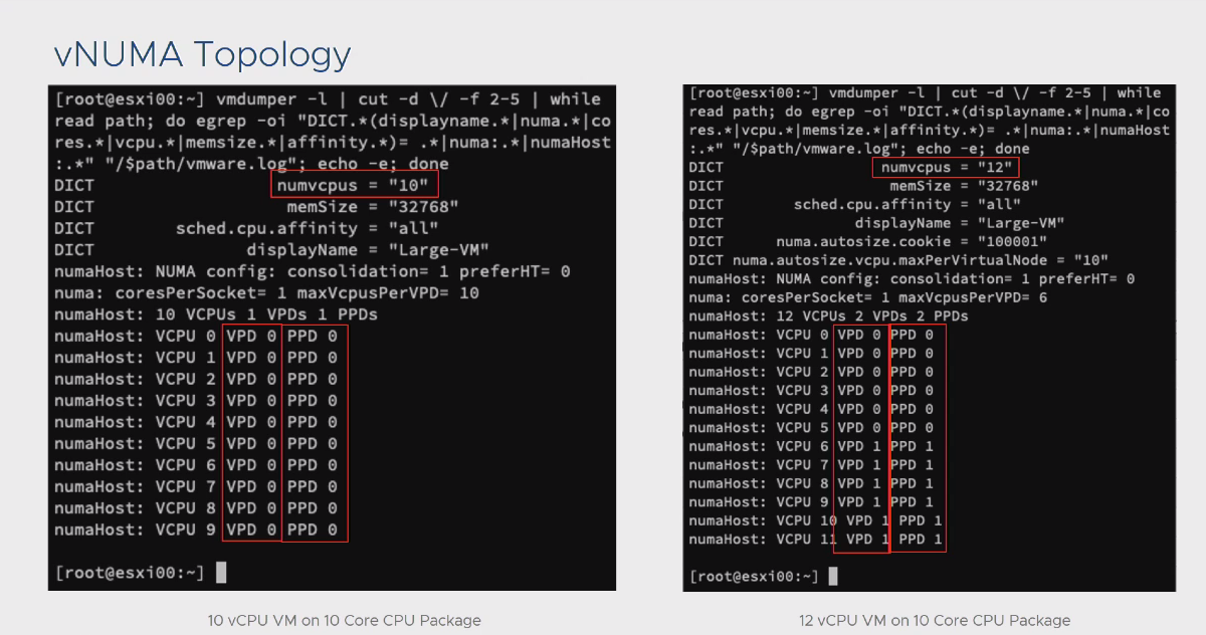
نکته: همانطور که گفته شد، NUMA Scheduler یک فرآیند کاملا Dynamic است. یعنی در هر 15 میلی ثانیه اقدام به بررسی وضعیت NUMA Node های موجود روی سرور فیزیکی شما می کند. در صورتیکه براساس الگوریتم های موجود، یک NUMA Node گزینه بهتری برای vCPU های ماشین مجازی شما باشد، اقدام به انتقال این vCPU ها به آن Node می نماید. این فرآیند انتقال هم در سطح vCPU و هم در سطح Memory رخ می دهد، اما با توجه به اینکه سرعت انتقال vCPU بسیار بالاتر از سرعت انتقال اطلاعات بر روی Memory می باشد، ممکن است در خروجی دستور ESXTOP خود و در بخش Memoery با ماشین های مجازی مواجه شوید که برای لحظاتی میزان استفاده از Remote Memory آنها بالا رفته است. این عدد را در بخش NRMEM می توانید مشاهده کنید.
یکی از مهمترین بخش هایی که در لایه Workload وجود دارد و شاید برای بسیاری از دوستان نامفهوم باشد، بخش مربوط به Cores Per Socket می باشد. این بخش به صورت مستقیم تاثیری در کارآیی سیستم ندارد و تنها برای مدیریت مباحث مرتبط با لایسنس طراحی شده است. اما به صورت غیر مستقیم می تواند بر روی عملکرد سیستم شما تاثیر نامطلوب بگذارد. این تاثیر نامطلوب متاثر از کوچک شدن دامنه های CPU می باشد. به 2 تصویر زیر نگاه کنید:
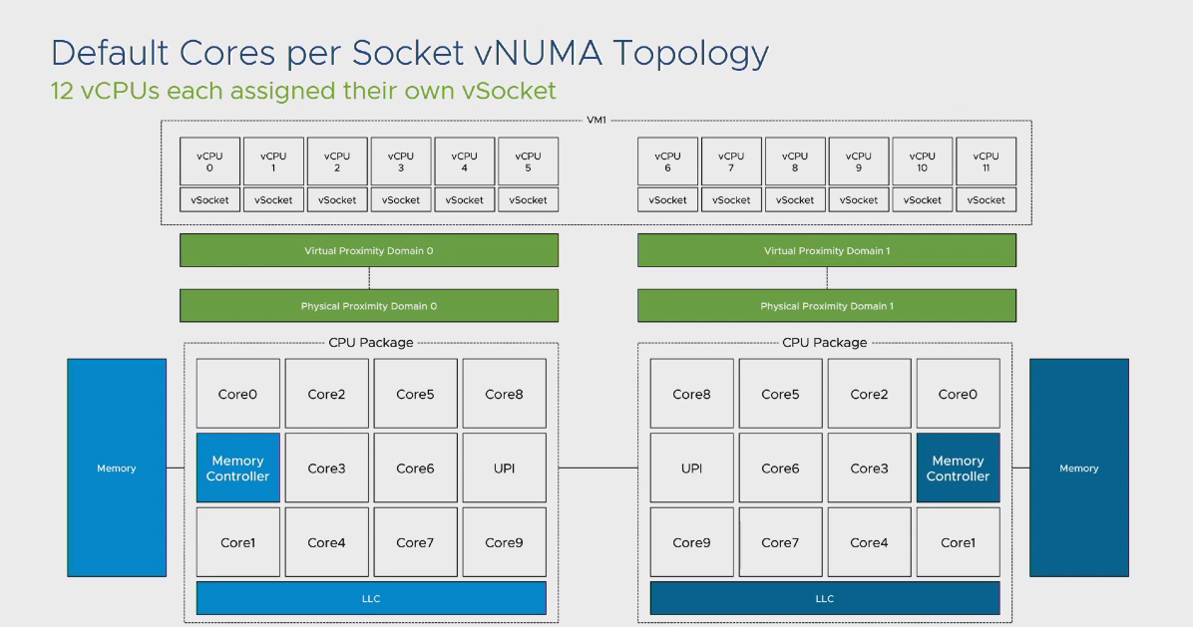
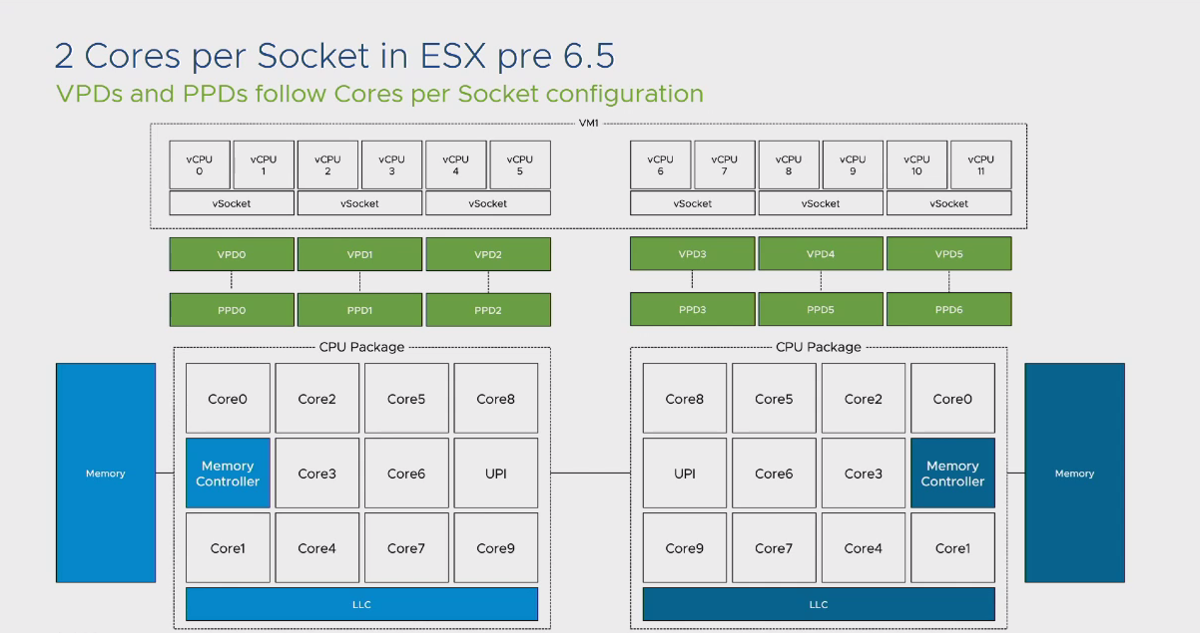
در این 2 تصویر تفاوت تخصیص Cores Per Socket بر روی یک ماشین مجازی را مشاهده میکنید. در حالت پیش فرض تنها 2 عدد PPD برای ماشین مجازی تخصیص داده شده است و برای حالت دوم این عدد به 6 افزایش یافته است. تفاوت این دو حالت در این است که ماشین مجازی شما در حالت اول 2 عدد NUMA Node را متصور می شود و خود را با این شرایط Optimize می کند و در حالت دوم با 6 عدد NUMA Node مواجه شده و خود را با این شرایط وقف خواهد داد. همین رفتار توسط اپلیکیشن هایی که NUMA Aware می باشند (مانند SQL Server) نیز رخ میدهد. نتیجه این موضوع این است که تصور Guest OS در حالت دوم این است که 6 سوکت فیزیکی و 6 بخش Local Memory وجود دارد و نحوه انتقال اطلاعات بر روی این بخش ها بر مبنای این تصور صورت می گیرد در صورتیکه در اصل موضوع، در لایه فیزیکی، شما تنها 2 عدد NUMA Node دارید و برای اپلیکیشن هایی که Cache Intensive می باشند، قطعا این رفتار می تواند یک رفتار مخرب از منظر Performance باشد.
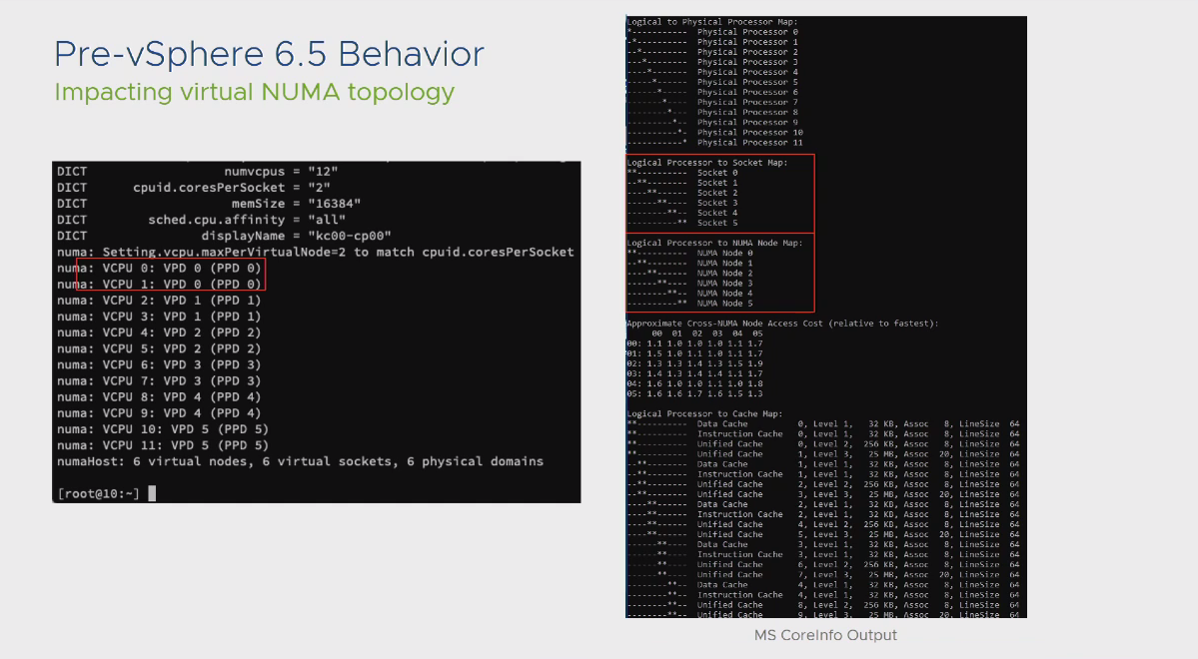
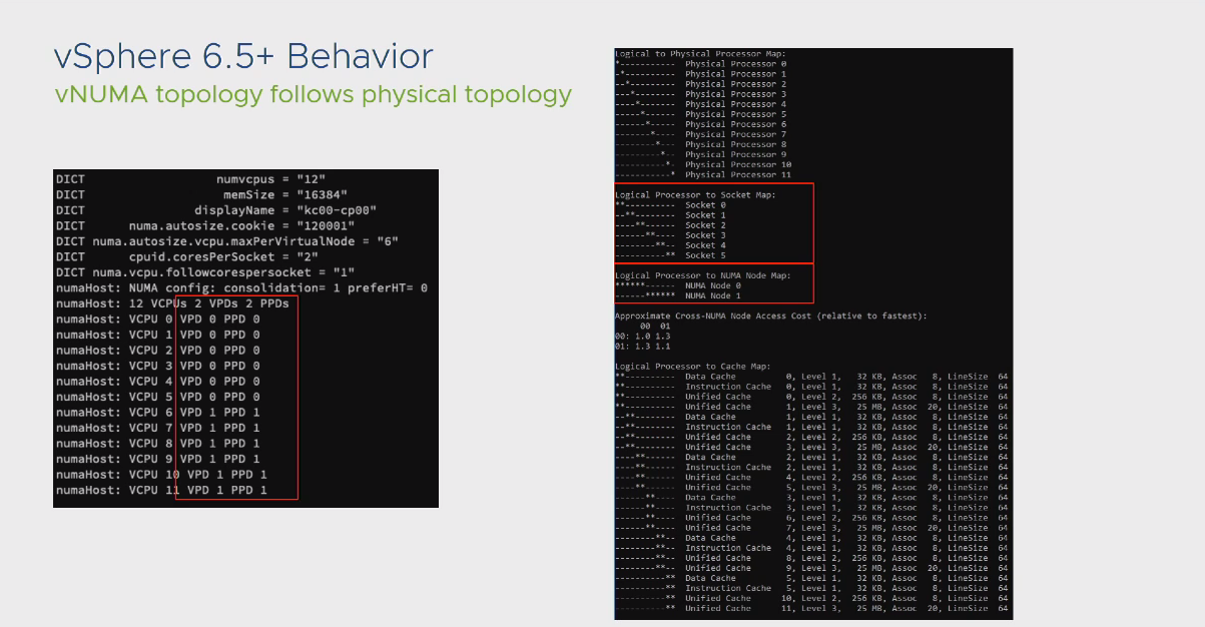
نکته: خبر خوش برای دوستانی که از نسخه های بالاتر از 6.5 استفاده می کنند این است که افزایش Cores Per Socket دیگر تاثیر مخربی در روند NUMA Scheduler ندارد. در تصویر زیر می توانید رفتار این نسخه در حالتیکه تعداد Cores Per Socket را افزایش داده ایم مشاهده نمایید:
تا به اینجا، تمام صحبت های انجام شده نسبت به vCPU و فرآیند NUMA Scheduler براساس این مفهوم بررسی گردید. اما در خصوص Memory به چه نحو رفتار می شود؟ به طور مثال برای ماشینی که تعداد vCPU های کمی دارد اما میزان Memory تخصیص داده شده به آن بیش از آن چیزی است که درون یک Local Memory وجود دارد چه اتفاقی رخ خواهد داد؟ در پاسخ به این سوال تصویر زیر را مشاهده نمایید:
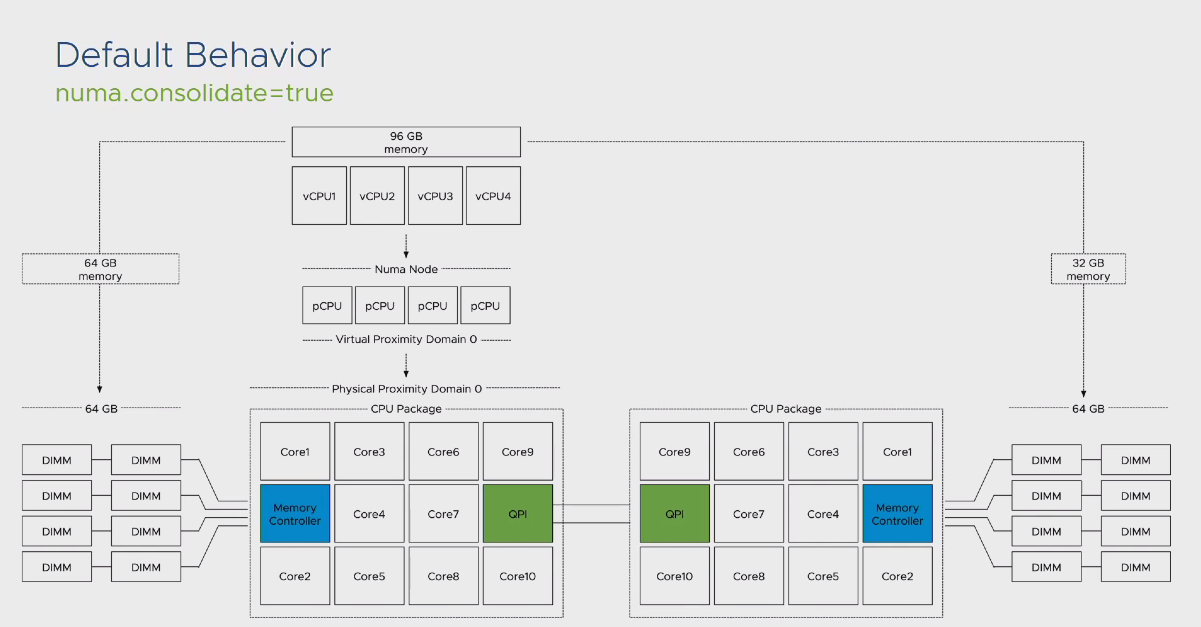
به صورت پیش فرض زمانیکه با چنین سناریویی مواجه شویم، استفاده از Remote Memory کاملا غیر قابل انکار است. اما با اعمال تغییراتی می توان مانع بروز چنین رخدادی شد. اولین تنظیم مربوط به numa.consolidate می باشد که در صورت تغییر مقدار آن به False تعداد PPD های تخصیص داده شده به ماشین مجازی تاثیر گذار از میزان Memory تخصیص داده شده به آن بر مبنای میزان Memory موجود بر روی یک Local Memory خواهد شد.
اما در خصوص VPD که وظیفه Expose کردن تعداد NUMA Node ها به Guest OS را بر عهده دارد اعمال نخواهد شد. در این شرایط سیستم عامل مجازی همچنان تصور میکند که یک NUMA Node دارد و خود را با این شرایط وقف می دهد در صورتیکه عملا میزان Memory تخصیص داده شده به آن بیش از میزان Physical Memory موجود در یک NUMA Node می باشد. در این صورت می بایست تنظیم دومی را هم برای ماشین مجازی خود انجام دهید. با تغییر عدد پیش فرض numa.vcpu.maxPerVirtualNode از 8 به عدد کمتر، براساس تعداد vCPU هایی که به ماشین مجازی خود اختصاص داده اید، می توانید تعداد VPD های خود را نیز به 2 افزایش دهید. در این صورت با روشن کردن ماشین مجازی خود، سیستم عامل مجازی با شرایط NUMA مواجه شده و خود را با این حالت وقف میدهد.
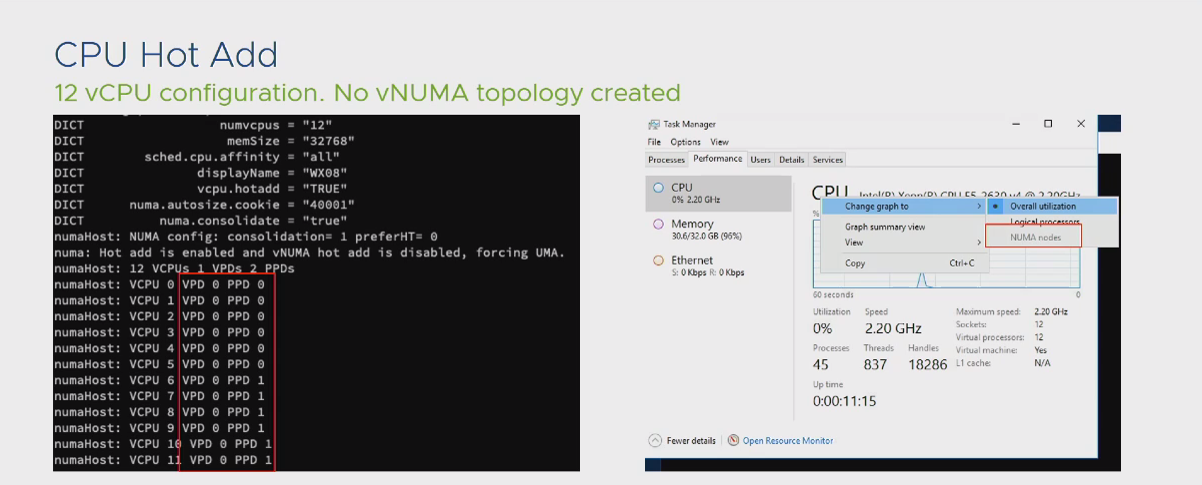
به عنوان نکته پایانی این مقاله، باید بدانید که در صورت فعال کردن گزینه CPU Hot Plug در سطح ماشین مجازی، تمام تنظیمات مرتبط با NUMA کاملا نقض شده و با هر نوع تنظیمی که ماشین مجازی خود را راه اندازی کرده اید، هیچ بهینه سازی NUMA در سطح ماشین مجازی رخ نخواهد داد. لذا در صورتیکه تنظیمات ماشین مجازی به شکلی است که نیازی به NUMA برای آن وجود ندارد از این گزینه بهره ببرید. این موضوع در خصوص Memory صادق نیست و فعالسازی گزینه Memory Hot Plug تاثیری بر روند NUMA Scheduler ندارد.
توجه داشته باشید که این مقاله در قالب یک وبینار رایگان به همراه اطلاعات بیشتر با همکاری موسسه نیک آموز اجرا شده است که در صورت تمایل می توانید از طریق این لینک ین وبینار را دانلود نمایید.
ببخشید، برای نوشتن دیدگاه باید وارد بشوید



