
در نهمین بخش از موارد اعلام شده برای VCP-DCV 2019 می خواهیم به توصیف کلاستر بپردازیم. هدف از ایجاد کلاستر چیست و با وجود کلاستر چه ویژگی هایی به محیط مجازی ما اضافه می شود موضوع مبحث این بخش می باشد.
همانطور که میدانیم، یک کلاستر در محیط مجازی در سطح یک دیتاسنتر ایجاد می شود. سرویس vCenter ما می تواند چندین دیتاسنتر را مدیریت کرده و هر دیتاسنتر نیز می تواند شامل چندین کلاستر باشد. یکی از دلایل مهمی که ما کلاسترهای مختلف در زیر یک دیتاسنتر ایجاد می کنیم استفاده خاص از ویژگی های آن می باشد که در ادامه می خواهیم در مورد این ویژگی ها صحبت کنیم.
اولین ویژگی که در جایگاه ویژه ای قرار دارد، ویژگی HA یا High Availability است. این ویژگی با مانیتور کردن تمام سرورهای یک RP و شناسایی خطاهای رخ داده اقدام به افزایش سطح دسترس پذیری سرویس در محیط مجازی می کند. برای این منظور یک Agent با عنوان معروف VPXA یا Virtual Provisioning X Agent بر روی هر هاست توسط سرویس vCenter نصب می شود. در برخی از مستندات به این Agent اصطلاحا Mini vCenter نیز گفته می شود. وظیفه اصلی این Agent ارسال Heartbeat به منظور اعلام سلامت سرور می باشد. علاوه بر این، مانیتور کردن میزان منابع موجود در RP شما به منظور مدیریت شرایط بحران یکی دیگر از وظایف این Agent می باشد. تصور کنید در یک کلاستر شامل 3 سرور، تعداد ماشین های مجازی شما به قدری باشد که تحمل از دست دادن یک سرور را نداشته باشید، هشدار این موضوع توسط این Agent به شما داده خواهد شد. این ویژگی می تواند Application های موجود بر روی ماشین های مجازی را نیز مانیتور کرده و در صورت بروز خطا بر روی آنها، اقدامات لازم را انجام دهد.
به صورت کلی ویژگی های کلیدی HA را می توان به شرح زیر اعلام کرد:
با فعالسازی این ویژگی در واقع شما میزان Downtime خود را به حداقل خواهید رساند و تمام این ویژگی ها به سادگی و تنها با در نظر گرفتن الزامات ساده و چند کلیک قابل دستیابی است. حال می خواهیم ببینیم این ویژگی به چه شکل کار می کند.
زمانیکه شما یک کلاستر ایجاد می کنید و این ویژگی را فعال می کنید، پس از نصب Agent، یکی از هاست های شما به عنوان هاست Master انتخاب می شود. این هاست وظیفه برقراری ارتباط با vCenter و مانیتور کردن وضعیت سایر هاست ها و تمام ماشین های مجازی محافظت شده در کلاستر را بر عهده دارد. همانطور که گفته شد این ویژگی وظیفه محافظت از ماشین های مجازی در مقابل بروز خطای هاست را بر عهده دارد که این خطاها می تواند یکی از موارد زیر باشد:
در حالت Failure یک هاست، عملکرد هاست کاملا متوقف شده و در واقع می توان گفت که آن هاست Crash کرده است.
در حالت Isolation یک هاست، شبکه آن هاست به صورت ایزوله در آمده است یعنی امکان برقراری ارتباط با Network Heartbeat را ندارد.
در حالت Partition یک هاست، ارتباط آن هاست با هاست Master قطع شده است.
این خطاها توسط هاست Master اعلام می شود، اما به منظور جلوگیری از هر نوع خطای عملکردی این سرویس، ارسال Heartbeat به هاست Master همیشه از دو کانال مجزا صورت میگیرد. یکی از این کانال ها وجود شبکه هاست ها می باشد و کانال بعدی ارسال Heartbeat به Datastore های موجود است. در صورتیکه یک هاست به دلیل وجود خطاهای شبکه ای، امکان ارسال Heartbeat به هاست Master را نداشته باشد، هاست Master از طریق Datastore هایی که قبلا معرفی شده اند اقدام به دریافت Heartbeat از آن هاست می نماید و در صورتیکه از این کانال نیز هیچگونه Heartbeat دریافت نکند، شرایط Failure را اعلام کرده و اقدام به ریست کردن ماشین های مجازی بر روی هاست دیگر می نماید.
یکی از Policy های مهم در ویژگی HA وجود گزینه ای به نام Admission Control می باشد. این ویژگی وظیفه تضمین وجود منابع کافی برای مدیریت شرایط بحران را بر عهده دارد. حالت پیش فرض برای این ویژگی Cluster Resource Percentage می باشد. در این حالت ابتدا شما میزان تحمل خطای هاست را مشخص میکنید و در ادامه در صورت نیاز می توانید تنظیمات پیش فرض را Override کرده و میزان درصد مدنظر برای رزرو نگه داشتن منابع CPU و Memory را مشخص کنید.
به غیر از حالت Cluster Resource Percentage دو حالت دیگر زیر نیز وجود دارند:
در حالت Slot Policy با تعیین میزان Slot به ازای ماشین های مجازی روشن می توانید Admission Control را مدیریت کنید.
در حالت Dedicated Failover Host یکی از هاست های خود را به عنوان Spare معرفی کرده تا در صورت بروز هر گونه خطا برای سایر هاست ها، جایگزی هاست آسیب دیده شود. در این حالت امکان قرار دادن ماشین های روشن تا زمان بروز خطا بر روی این هاست وجود ندارد و برای بسیاری از سناریوها می تواند Waste of Resource تلقی شود.
ویژگی DRS
یکی دیگر از ویژگی های سطح کلاستر، ویژگی DRS یا Distributed Resource Scheduler می باشد. این ویژگی با مانیتور کردن Workload شما می تواند اقدامات پیشگیرانه انجام دهد و ماشین های مجازی را به صورت Live از یک هاست به هاست دیگر منتقل کند. به منظور دستیابی به این ویژگی ابتدا می بایست شبکه vMotion خود را پیکربندی کنید و در نهایت با حصول اطمینان از اینکه تمام CPU های موجود بر روی هاست های شما از یک خانواده و از یک نسل می باشند، اقدام به فعالسازی این ویژگی نمایید. در صورتیکه پردازنده های موجود بر روی هاست های شما از یک نسل نباشند، می بایست ابتدا اقدام به فعالسازی EVC نمایید. روند بهینه سازی Workload توسط این ویژگی یا به صورت Automatic یا Manual انجام می شود. در حالت Automatic سیستم با تشخیص خود اقدامات لازم را نیز انجام می دهد و در حالت Manual پس از تشخیص با اعلام هشدار، به شما اعلام می کند تا وارد عمل شوید.
با استفاده از ویژگی DRS شما می توانید از تولید قوانین متعدد به منظور مدیریت Workload خود نیز بهره ببرید. این قوانین به صورت کلی به دو دسته تقسیم می شوند:
دسته اول به منظور قراردادن ماشین های مجازی کنار هم یا بر روی یک یا چند هاست می باشد و دسته دوم برای جداسازی ماشین های مجازی از هم یا عدم قرارگیری آنها بر روی یک یا چند هاست می باشد.
از منظر ویژگی DRS یک Workload شامل منابع پردازشی CPU و Memory می شود. از نسخه 6.5 به بعد، شرایط Network نیز در این بخش لحاظ گردید و بدین ترتیب ویژگی DRS وضعیت شبکه یک هاست را در تصمیمات خود لحاظ می کند.
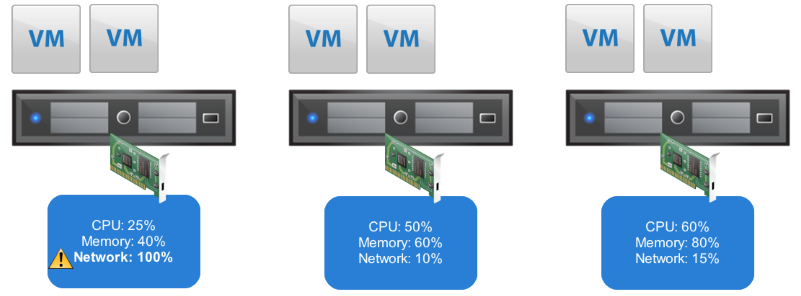
در این ویژگی گزینه ای با عنوان Predictive DRS وجود دارد. این ویژگی به سرویس vCenter این اجازه را می دهد تا براساس رفتارشناسی که در یک بازه زمانی از ماشین های مجازی شما انجام داده است، نسبت به برقراری تعادل ماشین های مجازی بر روی هاست ها مختلف اقدام کند. برای روشن تر شدن این ویژگی به این مثال توجه کنید. در محیط مجازی شما 4 ماشین وجود دارد که هر کدام از آنها سرویس مشخصی را ارائه می کنند. ماشین اول به صورت روزانه و در ساعات منتهی به صبح، بیشترین مصرف منابع را دارد که این وضعیت بر روی سایر ماشین های مجازی شما تاثیر منفی میگذارد. ویژگی DRS نیز با در نظر گرفتن Workload شما در زمانی که تشخیص می دهد عمل جابجایی مورد نیاز است اقدامات لازم را انجام میدهد. اما این اقدام زمانی رخ میدهد که اثرات منفی آن بر روی سایر ماشین های مجازی دیده شده است. حال با فعال کردن گزینه Predictive DRS سرویس vCenter شما بعد از شناختی که نسبت به آن ماشین مجازی پیدا کرد، می داند که این ماشین مجازی در ساعات مشخصی مصرف منابع بالایی دارد و لذا قبل از رسیدن به ساعات اوج مصرف آن، اقدام به جابجا کردن آن ماشین مجازی و جلوگیری از بروز اثرات منفی آن بر روی سایر ماشین های مجازی می نماید. اما نکته بسیار مهم این است که این ویژگی اطلاعات مورد نیاز خود را از سرویسی به نام vRealize Operations Manager می گیرد و در صورت عدم راه اندازی این سرویس در محیط مجازی خود نمی توانید از این ویژگی بهره ببرید.
مطالب بالا تمام آنچه که برای این بخش مورد نیاز بود را شامل می شود اما از مطالعه فایل های PDF ارائه شده توسط شرکت VMware غافل نشوید. برای آشنایی با بخش های دیگر این صفحه را دنبال کنید.
ببخشید، برای نوشتن دیدگاه باید وارد بشوید




